This post previously appeared on my blog, 'Absolutely No Machete Juggling'.
Contents
- What’s wrong with GitFlow?
- Introducing Three-Flow
- Releasing
- Release Notes
- Common Operations
- How do I cut a release candidate off master?
- How do I release a candidate?
- How do I find which branches have a particular commit on them?
- How do I find which tag a branch is pointing to?
- How do I find out which commits are going to go out with a release?
- How do I set up the candidate and release branches for the first time?
- Questions
- Isn’t this just cactus model?
- Isn’t this just GitFlow without feature branches?
- What about code reviews?
- What about a codebase with multiple artifacts?
- Is there a way to not have to manually type so many arguments?
- Can’t I just use merging for the release branch?
- Summary
Of all the conversations I find myself having over and over in this field, I think more than anything else I’ve been a broken record convincing teams not to adopt GitFlow.
Vincent Driessen’s post “A successful Git branching model” – or, as it’s become commonly known for some reason, “GitFlow” – has become the de facto standard for how to successfully adopt git into your team. If you search for “git branching strategy” on Google, it’s the number one result. Atlassian has even adopted it as one of their primary tutorials for adopting Git.
Personally, I hate GitFlow, and I’ve (successfully) convinced many teams to avoid using it and, I believe, saved them tremendous headaches down the road. GitFlow, I believe, leads most teams down the wrong path for how to manage their changes. But since it’s such a popular result, a team with no guidance or technical leadership will simply search for an example of something that works, and the blog post mentions that it’s “successful” right in the title so it’s very attractive. I’m hoping to possibly change that with this post, by explaining a different, simpler branching strategy that I’ve used in multiple teams with great success. I’ve seen GitFlow fail spectacularly for teams, but the strategy I outline here has worked very well.
I’m dubbing this Three-Flow because there are exactly three branches. Not four. Not two. Three.
First, a word of warning. This is not a panacea. This will not work for all teams or all kinds of development work. In fact off the top of my head, I don’t believe it would work well for 1) embedded programming 2) shrinkwrap release software or 3) open source projects. Basically Three-Flow works when:
- Everyone committing to a codebase works together. If not on the same team, at least at the same company. If you’re taking code from external developers via GitHub or something, this won’t work. Everyone making commits is “trusted.”
- The product can be replaced live with another version without user awareness. In other words, hosted web applications and SaaS offerings.
What’s wrong with GitFlow?
In brief, the primary flaw with GitFlow is feature branches. Feature branches are the root of all evil, pretty much everything that results from using feature branches is terrible. If you take nothing else away from this post, or hell even if you stop reading entirely, please internalize an utter disgust for feature branches.
To be fair, Driessen’s post specifically does say that feature branches “typically exist in developer repos only, not in origin” but the graphics really don’t convey that very well, including a specific image of “origin” which includes a pink feature branch with three commits. Moreover, I’ve encountered many teams that have adopted or are considering adopting GitFlow and none of them have ever noticed that Driessen recommends branches only exist on a developer’s machine. Everyone I’ve ever met that adopts GitFlow has long-running remote feature branches.
There’s nothing wrong with making a feature branch on your local machine. It’s a good way to hop between different features you might be working on, or have a clean master in case you need to make a commit to mainline without pulling in what you’re working on. But I’ll go further than the original GitFlow post and say feature branches should never be pushed to origin.
When you have long-running feature branches, integration hell is almost inevitable. Two engineers are happily working away making commit after commit to their own respective feature branches, but neither of their branches are seeing the other’s code. Even if they’re regularly pulling off mainline, they’re still only seeing the commits that make it into the main branch, not each others. Developer A merges their code into mainline, then Developer B pulls and merges theirs, but now they have to deal with tons of merge conflicts. Developer B might not be in the best position to understand and resolve those conflicts if they don’t fully understand what Developer A is doing, and depending on how long these branches have been alive, they might have tons of code to resolve.
Long-running feature branches are the exact opposite of what you want. A developer’s primary form of communication with other developers is source code. It doesn’t matter how often you have stand-up meetings, when it comes to the central method of communication, long-running branches represent dead silence. Long-running branches are the worst.
Feature branches also scale terribly. You can get away with one developer having a long-running feature branch, but as your team grows and you have more and more engineers in the same codebase, each pair of developers running feature branches is failing to communicate effectively about their work. If you have a mere 8 engineers each running their own feature branch, you have \(\frac{8^2}{2} = 32\) different failed communication lines. Add another engineer and it’s 40 missed lines of communication.
Use Feature Toggles
Instead of using feature branches, use feature toggles in your code. Feature toggles are essentially boolean values that allow you to not execute new code that isn’t ready for production while still sharing or possibly even deploying that code. It looks in code exactly as you might expect:
if(newCodeEnabled) {
/*new code*/
} else {
/*old code*/
}
The old code will continue executing until the newCodeEnabled toggle is flipped. These toggles can be implemented through a config file or even some kind of globally accessible boolean, though in my experience the best way is to use an external config like Consul or Zookeeper so that features can be toggled on or off without requiring a redeployment. Product owners and other stakeholders love being able to view a dashboard of toggles and turn features on and off without asking developers.
If two developers are working from the same branch but using different feature toggles, the chances for a conflict are far lower. And since they’re working off the same branch, they can pull and push multiple times per day to stay in-sync. At a bare minimum, developers should pull at the start of the day and push at the end of the day, so that no two local repositories are out of sync by more than a workday.
Automated tests should be written for the cases where the toggle is both on and off. This basically means that when a new feature is being developed, the existing tests simply need to be adjusted to setUp with the flag off. Then new tests get added with the flag on. The test suite ensures that the “old way” never breaks. Sometimes the execution path through the code can be affected by more than one toggle. If you have two toggles that intersect in some way, you need 4 groups of tests (both off, both on, and both variants of one on and one off). Again this ensures that two developers working in the same area of the code are regularly seeing each other’s changes and integrating constantly. Code coverage tools can easily tell you if you’re missing a potential path through the code.

Feature Toggles can also be expanded to be more dynamic. Rather than simply being booleans, you could build your system so that toggles could depend on the status of users, allowing users or groups of users to “opt-in” to a beta program that gives access to bleeding edge features as they’re developed to solicit customer feedback. Toggles could be dependent on geographic location or even a dice-roll, allowing for A/B testing and canary releases when features are ready to be turned on.
When the feature is finished and turned on in production, you can schedule a small cleanup task to delete the old code paths and the toggle itself. Or you can leave the code in place if it’s a feature that may have reason to turn off again in the future - I’ve left feature toggles in place that have really saved the day down the road when some major backend system was experiencing a catastrophic problem and stakeholders wanted to simply turn the feature off temporarily. If you do intend to remove the toggle, it’s a good idea to schedule it into your regular process as soon as you start the feature, lest the team forget when bigger, shinier work comes along.
I cannot overstate the value of feature toggles enough. I can virtually guarantee that if you start using toggles instead of branches for long-developed features, you’ll never look back or want to use feature branches again. In nearly every case that I gave in to a team member that pushed hard for a feature branch because of this or that reason, it wound up being a massive pain later on that delayed the release of important software. I’ve pretty much always regretted feature branches, and never once regretted making a feature toggle. It takes some getting used to, particularly if you’re accustomed to long-running branches, but the positive impact toggles have on your team is tremendous.
Introducing Three-Flow
Alright, now that we’ve gotten feature branching off the table, we can talk about the workflow that I’ve used successfully on multiple teams.
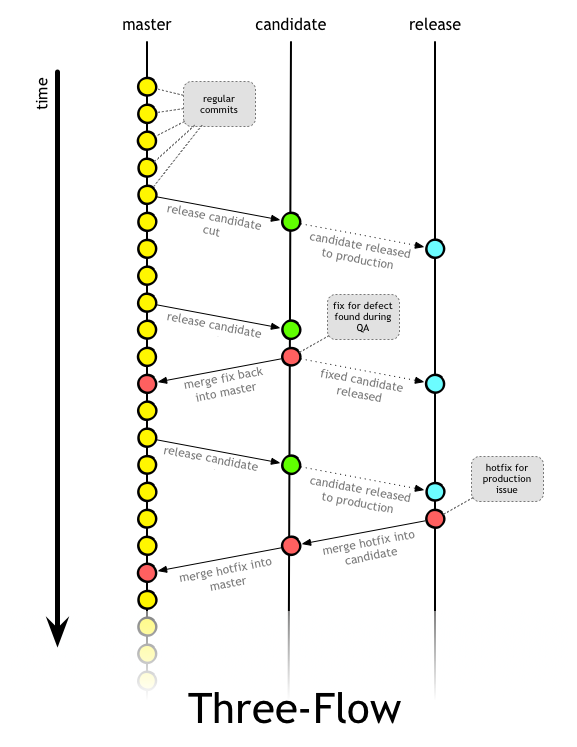
In this approach, all developers work off master. If a feature is going to need to be in development for a while, it’s put behind a feature toggle, and still kept on master with all the other code. All commits to master are rebased. It’s a good idea to set automatic rebase on pulls. If you have a local feature branch for your work, it should be rebased onto master, there should be no trace of the branch in origin.
That’s it. That’s where all the main development work happens. You have one branch, the default master branch. And everyone codes there. Everything else about Three-Flow is concerned with managing releases.
Releasing
When it’s time to do a release (regular cadence or whenever the stakeholders want it, your call), the master branch is “cut” to the candidate branch. The same candidate branch is used over and over again for this purpose.
The purpose of candidate is to allow a QA team to do any kind of regression testing it would like to do. Theoretically, all of the features themselves have been tested as part of accepting that the work is done. But this release candidate branch allows one last check to make sure everything is in order before going to production. The master branch where all the work is done and accepted should be tested in a production-like environment where the relevant feature toggles are on. The candidate branch where work is sanity-checked before release should be tested in a production-like environment where the relevant feature toggles are off. In other words, it should run the code the same way that production itself will, with the new toggles defaulted to off.
To cut a release candidate, you’d do this:
$ git checkout candidate #assume candidate already tracks origin/candidate
$ git pull #make sure we're up to date locally
$ git merge --no-ff origin/master
$ git tag candidate-3.2.645
$ git push --follow-tags
The reason for using --no-ff is to force git to create a merge commit (a new commit with two parents). This commit will have one parent that’s the previous HEAD of candidate and one that’s the current HEAD of master. This allows you to easily view your git history and see when branches were cut, by whom, and which commits were pulled over.
You’ll also noticed we tagged the release. More on that in a bit.
If bugs are found in the candidate branch as part of the testing effort, they are fixed in candidate, tagged with a new release tag, and then merged down into master. These merges should also use the --no-ff parameter, so as to accurately reflect code moving between the two branches.
When a release candidate is ready to go out the door, we update the release branch so that it’s HEAD points to the same commit as the HEAD of the candidate branch. Since we’re tagging every release we make on the candidate branch we can simply push the tag itself to be the new HEAD of release:
$ git push --force origin candidate-3.2.647:release
The --force basically means to ignore whatever else is on the origin release branch and set it’s HEAD to point at the same commit that candidate-3.2.647 points to. Note that this is not a merge - we don’t want to complicate the git history with this, really the only reason we’re even bothering with the release branch at all is so that we have a branch to make production hotfixes to if need be. Yes, this force push means any hotfix work in release would get overwritten - if you find yourself releasing new candidates to production while there is ongoing hotfix production work, your team has a serious coordination/communication issue that needs to be addressed. Either that or you’re doing way too many production hotfixes and have a major quality problem. Production hotfixes should be possible but rare.
The reason we do a push --force rather than a merge is that if you do a merge, it means that the commit at the HEAD of candidate and the commit at the head of release may have different sha-1’s, which isn’t what we want. We don’t want to make a new commit for the release, we want exactly what was QA’d and that’s the commit at the HEAD of candidate. So rather than create a merge, we forcefully tell git to make the tip of release exactly match that of the release candidate, the HEAD of candidate.
Any production hotfixes that need to happen are made to release and then merged into candidate and then into master, all with --no-ff. This is quite a bit of git work for a production hotfix (2 distinct merge operations), but production hotfixes should be rare anyway.
If you follow this workflow exactly, then when you view your git history as a graph it will look pretty much exactly like the above picture, showing exactly which commits moved between branches.
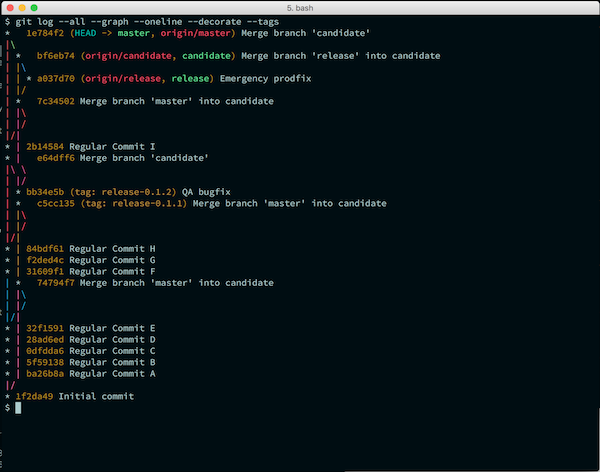
You’ll notice that the way the above graph does NOT resemble the earlier picture is that you don’t see the dotted lines pushing to release except the most recent one. That’s because we always do a --force push, meaning that every time we release to production, we completely ignore what production once was. This is intentional - it doesn’t matter what was on production and when, all that matters is what’s on production right now so we can hotfix it in case of a production emergency. The only time you’ll even see the release branch at all on this graph is for whatever is currently in production, and whenever hotfixes were made that had to be merged into candidate and master. This is exactly what we want: no unnecessary information adding noise to our graph.
Release Notes
You can easily generate “release notes” for a deployment to production. You just need to compare the tag for the current release branch to the tag for the current candidate branch.
If you’re using tags, you can do this comparison by using the tag names. It’s easy to remind yourself of which tag is in production, because every time we force an update of the release branch pointer, we use the tag. That means that there’s always exactly a tag that points to the same commit that the HEAD of release points to. You can find out which tag this is by running:
$ git describe --tags release
candidate-3.1.248
So if we know that our candidate branch has been tagged as candidate-3.2.259 you can get the list of commits that make up the difference between those two tags like so:
$ git log --oneline candidate-3.1.248..candidate-3.2.259
You could also do this if you didn’t want to mess with tags. The following will always just compare what’s on release (production) with what’s on candidate (what’s planned to go to production):
$ git log --oneline release..candidate
Running these commands will show you every single commmit that is in the new candidate that wasn’t in the previous release. At my last gig, we liked to include the ticket numbers for our issue tracker in our commits, which allowed a script to cross-index this list of commits with actual work items in Jira.
Common Operations
Just to summarize a bit, here are some of the operations you might want to be able to do. All of these examples assume that your local branches are properly set up to track the remote branches, and that those local branches are up to date. If you’re not sure, it’s often a good idea to do a git fetch and then use names like origin/master instead of master to ensure you’re using the origin’s version of the branch in case yours is stale.
How do I cut a release candidate off master?
$ git checkout candidate
$ git pull
$ git merge --no-ff master
$ git tag candidate-3.2.645 #optionally tag the candidate
$ git push --follow-tags
How do I release a candidate?
$ git push --force origin <tag for the candidate>:release
Alternatively if you aren’t using tags you could just do:
$ git push --force origin candidate:release
or, if you’re not sure you’re up to date locally:
$ git fetch
$ git push --force origin origin/candidate:release
How do I find which branches have a particular commit on them?
Often people want to know if a particular code change is currently in production or set to go out to production in the next release. Here’s an easy way to find which of the three branches a commit is on.
$ git branch -r -contains <sha of commit>
How do I find which tag a branch is pointing to?
Or in more accurate terms, for a given branch pointer, how do I find which tag(s) point to the same commit as the branch HEAD?
$ git describe --tags <branch>
How do I find out which commits are going to go out with a release?
$ git log --oneline release..<tag of release candidate>
You could also do this if you didn’t want to mess with tags:
$ git log --oneline release..origin/candidate
How do I set up the candidate and release branches for the first time?
You can create what’s called an ‘orphan’ branch with no commits to it, but you’ll be unable to push it to origin to set up the remote branch until you have some kind of commit.
Pretty much every project starts with an initial commit, usually just a readme or something. I recommend just making a branch off that commit and pushing that. What you’re looking for is the first merge commit into candidate to have two parents so that it shows up in logs correctly. So really, any commit on candidate will work, may as well choose the first one.
$ git branch candidate `git log --format=%H --reverse | head -1`
$ git checkout candidate
$ git push
If you try the approach where you create a fresh orphan commit, you’ll find that the first time you try to merge, git will tell you “refusing to merge unrelated histories”. You basically need the branches to all share a commit, so it may as well be the first commit. Word of warning though, you might get merge conflicts the very first time you actually cut a release candidate (but probably not).
To set up the release branch for the first time, just do a release. As soon as you force push the right commit to the remote release branch, it will be set. You’ll also want to check out a local copy of the same branch for any hotfixes you may want to do:
$ git branch release
$ git branch release --set-upstream-to=origin/release
Questions
Isn’t this just cactus model?
You may be wondering if Three-Flow is simply Jussi Judin’s cactus model, an alternative to GitFlow that uses the default master branch for all development work.
For the most part, yes, it is. The key difference is that Judin recommends moving commits between the master and release branches via cherry-picks. I very much recommend against that, cherry-picks are a last resort, to only be used when correcting a mistake. I prefer rebasing to merging, and I prefer merging to cherry-picking. I think it’s important to be able to use merge commits to actually see when and what commits were merged, and by whom. Being able to pull up an accurate graph of merges is important. I only use cherry-picking when I put a commit on the wrong branch by mistake.
The other main difference is the candidate branch which I accept as something of a necessary evil. While my goal is always an always-deployable master where all commits automatically go to production, I’ve found that most organizations and teams are not ready or comfortable with that kind of deployment schedule. Most groups like to have some kind of QA buffer time and that’s basically what candidate provides. The goal of the team should be to remove the need for the candidate crutch but in the mean time Three-Flow provides a very usable, simple branching model that generally gives teams everything they need to be successful with git.
Isn’t this just GitFlow without feature branches?
I have actually explained this branching strategy to GitFlow adopters by telling them it is essentially just GitFlow except that you don’t have feature branches, all development happens on develop but you rename GitFlow’s develop to master and you rename GitFlow’s master to release.

Always 3 there are. No more, no less.
The motivator behind Three-Flow is simplicity. GitFlow encourages the creation of a multitude of feature branches, release branches, and hotfix branches. As a project goes on, the log can start to look impossibly complex. With Three-Flow, there are no feature branches or hotfix branches. Hotfixes simply happen on the production release branch. And instead of having multiple release branches, you have a single candidate branch that you just keep reusing.
You don’t need a system of what to name your branches because there are literally exactly three branches in origin: master, candidate, release.
Answering the question of “where does my code go?” is very straightforward. Is it a production hotfix? If so, it goes in release. Is it fixing a bug that was found while QAing the release candidate? If so, it goes in candidate. Anything else and it goes in master.
What about code reviews?
Code reviews are just a gate on master, so you use this same process but instead of committing directly to master, you commit however your code review tool requires. You can do this by creating short-lived feature branches just for the purpose of gating a commit to master, or whatever your code review tool prefers.
What about a codebase with multiple artifacts?
A lot of people have a single codebase that builds multiple, independently deployable artifacts. Those individual buildable artifacts need their own separate QA cycles and different artifacts will have different version numbers in production. How does Three-Flow work with such a setup?
I’ve actually worked this way very recently. We had a single git repository that built multiple different artifacts that deployed independently. The solution was simple, and each independent artifact only adds two branches to Three-Flow.
You still have a single shared codebase in master and you use feature toggles instead of branches. But let’s say you have two artifacts foo and bar. You simply have a foo_candidate, foo_release, bar_candidate, and bar_release. When you tag release candidates, you tag in the format foo-candidate-2.1.423 and bar-candidate-3.2.126.
Otherwise the process works exactly the same way. This scales better than you might expect, I was very recently on a large project that had 4 different independently deployable artifacts that came out of a single codebase. 8 candidate and release branches, plus master. Generally there was a pretty strong mapping between an individual “team” and one of these artifacts, so a team or a group still just worked with 3 branches.
Is there a way to not have to manually type so many arguments?
One of the weirder aspects of this flow is that pretty much every command I suggest typing into git has additional arguments.
Any time you do a merge, I’m asking you do to a merge --no-ff. When you cut a release and tag it I suggest you push using push --follow-tags so your tag gets up to origin as well.
You can actually set these arguments to be defaults. Since all merging in Three-Flow uses --no-ff, you’re safe to run:
$ git config --global merge.ff no
If you run this then from that point on you can simply run git merge without the --no-ff argument.
Similarly, you can set push to always push locally-created tags:
$ git config --global push.followTags true
And I mentioned this up above but it’s a good idea to set your master branch to automatically rebase whenever you pull. You can do this like so:
$ git config --global branch.master.rebase true
You can actually set any new branch to automatically rebase on pulls in case you’re making local feature branches that track master:
$ git config --global branch.autosetuprebase always
You could leave out the --global from any of these commands so the configuration only applies to the specific git repository you’re working in, as well.
Can’t I just use merging for the release branch?
First of all, you can do whatever you want. This is just a strategy that worked for me on multiple different teams and I wanted to spread it around because I think it’s much simpler than GitFlow.
But moreover, yes, if you don’t like the idea of doing a push --force to update release and losing some historical information, but would rather just do a merge --no-ff, by all means do it. This has the advantage of being fewer things to remember how to do, basically any time you move code between the three branches you’re doing a merge --no-ff.
In fact, an early version of this strategy did just that, --no-ff merges to release. It worked out fine, reading the git history was really straightforward. The only thing I don’t like about it is that it’s kind of a fib, in that what goes out to production should be the exact same HEAD of candidate that went through QA, and doing a merge commit creates a brand new commit on release that didn’t necessarily get tested. You could, of course, not do a merge commit to release and only do fast-forwarding commits. But then you sort of lose the history anyway, and there’s always a chance that the branch can’t be fast-forwarded and you need a merge commit anyway. And forget about rebasing to release, you’re pretty much guaranteed to have to work your way through a ton of merge conflicts, often very similar ones over and over as you individually resolve each commit in the release.
For my money, doing the force pushes kind of reinforces that release isn’t really a branch and shouldn’t be treated like one. It’s really just an updated pointer to production. It’s basically just a series of tags, except that since it’s a branch you can easily make a new commit on it for production hotfixes. To each their own though, there are definitely some simplicity advantages to always doing the same thing with candidate that you do with release. But hell, either way is preferable to using GitFlow. Have I mentioned how much I hate GitFlow? It’s like, a bunch.
Summary
To summarize the main Three-Flow branching model outlined here:

It's dangerous to git alone. Take this.
- There are three branches in origin:
master,candidate,release - Normal development happens on
master. All new commits are rebased. - Features that are incomplete are put behind feature toggles, ideally dynamic toggles that can be changed without a redeploy
- To cut a release,
masteris merged intocandidatewith a--no-ffmerge commit - Any bugs found during a candidate’s QA phase are fixed in
candidateand then merged intomasterwith a--no-ffmerge commit - When a candidate is released to production, it’s
push --forced to the tip ofrelease - Any production hotfixes happen in
releaseand are then merged intocandidatewhich is then merged intomaster.
That’s really all there is to it. Like I say above, there are all kinds of development paradigms that this won’t apply to, it’s largely geared toward web applications. But if you think Three-Flow might work for your organization, I highly recommend giving it a shot before adopting the future headache and incomprehensible git history that is GitFlow.
In my opinion, Three-Flow is the quickest and easiest way to get up and running with a sensible branching strategy with minimal rules to follow and the fewest complexities to understand.
Tried something similar and loved it? Tried something similar and found an issue that you solved? Think my use of --force is a blasphemous use of git and I’m the stupidest dumb idiot that ever ate his own boogers? Feel free to leave a comment below.